- 출처: 도메인 주도 설계 - 에릭 에반스
- 도메인 객체의 생명주기
일반적으로 객체를 사용하는 과정을 생각해보자. 생성자로 객체를 생성한 뒤 연산에서 사용하며 직접 해제하거나 참조관계를 끊으면 GC와 같은 수집기로 보내져서 소멸하는 과정을 거치게 된다.
도메인 객체는 이런 기본적인 생명주기 말고도 특별히 더 고려해야하는 점들이 있다. 우선 생명주기 동안 무결성을 유지해야 하며 생명주기를 관리해주어서 모델이 난해해지는것을 방지한다. 이 말을 지금 당장은 자세하게 이해하지 못해도 상관없다. 뒤이어 설명할 aggregate 항목을 보면 완전히 이해할 수 있을것이다.
DDD에서는 이를 해결하기 위해 Aggregate(집합체), Factory, Repository 3 가지 패턴을 제시한다.
- Aggregate: 도메인 객체의 무결성을 유지하며 소유권과 경계(boundary)를 명확하게 해준다. 또한 객체간의 연관관계(association)이 혼란스럽지 않도록 해준다.
- Factory: 복잡한 객체 및 Aggregate를 생성하고 재구성하며 내부 구조를 캡슐화한다.
- Repository: 생명주기의 중간과 마지막을 담당한다. infrastructure 계층을 캡슐화하며, 영속 객체를 조회한다.
3 가지 패턴을 나열해서 마치 상황에 따라 택하는 문제로 오해할 수 있는데 택1의 문제가 아니며 협동관계에 있다. 비즈니스 문제를 해결하기 위해 Aggregate를 모델링하며, 설계에 Factory와 Repository를 추가하면 객체의 생명주기 동안 체계적이고 의미있는 단위로 조작될 수 있게 도와준다.
- Aggregate (집합체)
이전에 SW에서 모델을 표현하는 요소에서 Entity, VO, Service와 같은 용어는 의미를 아주 깊게 이해하고 사용하진 않았더라도, 비교적 친숙하게 느껴졌을것이다. Aggregate라는 개념은 모델을 표현하는 새로운 개념일까? Aggregate는 아주 단순하고 무식하게 표현하자면 Entity와 VO를 모은것이라고할 수 있다. 뒤에 설명하겠지만 따로 써도되는데 굳이 모은 이유는 이점이 있기 때문이다.
객체의 연관관계(association)를 최소화하면 탐색이 단순해지는 이점이 있으나 현실세계는 그렇게 호락호락하지 않다. 그래서 객체의 연관관계를 있는 그대로 표현하게 되면 시스템이 상당히 복잡해지게 된다. 이런 복잡한 관계의 객체들을 그대로 사용하지 않고 묶어서 경계(boundary)를 설정해주면 이해하기가 더 수월해지는데 이렇게 묶인 단위들을 aggregate라고 할 수 있다.
DB에서 Person 객체를 삭제한다고 가정해보자. 이런 Person 객체는 보통 이름, 생년월일, 주소 등과 같은 속성을 갖는다. 시스템에서 Person을 삭제하면 이런 속성들도 자연스럽게 삭제된다. 하지만 주소와 같은 경우 다른 Person 객체도 동일 주소를 참조하고 있다면 문제가될 수 있다. 객체 변경의 범위를 명확히 하지 않으면 시스템이 커질 때 문제가 될 수 있다. 물론 DB의 rollback이나 lock과 같은 기술적인 해법을 통해 일관성을 보장해줄 수 있지만 기본적인 이는 모델링 문제의 해법을 간과한것이다.
따라서 데이터 변경의 단위로 다루는 연관 객체의 묶음 즉 범위(boundary)가 필요하다. 이를 aggregate 라고 하며 아래와 같은 특징을 갖는다.
- Aggregate는 Root와 Boundary가 존재한다.
- Boundary는 무엇이 포함되고 포함되지 않는지를 정의한다.
- Root는 하나만 존재하며, Aggregate 내의 특정 Entity이다.
- Boundary내 객체는 서로 참조가 가능하며, 외부에서는 Root만 참조가능하다. Root entity는 전역 식별성을 지니며, 이외의 entity는 지역 식별성을 지닌다.
위의 특징을 염두해두고 자동차 수리점 S/W를 구축한다고 가정해서 Aggregate를 구성하는 과정을 살펴보자.
- 보통 수리대상을 자동차로 식별할것이다. 따라서 이를 전역 식별성을 지닌 entity로 생각할 수 있다. 자동차를 식별하기 위해 차량 식별번호를 활용한다고 가정하자.
- 자동차에는 엔진이나 타이어 같은 여러가지 부품이 있다. 자동차를 수리하는 입장에서 타이어를 관리할때에는 주행거리나 로테이션과 같은 이력을 따질것이다. 각 타이어를 식별하려면 entity여야 한다. 또한 엔진도 역시 식별되므로 entity가 된다.
- 타이어를 식별하려고할 때 "어떤 자동차의 타이어"를 식별하고 싶은 경우는 있어도 타이어를 개별적으로 식별하려고 하는 경우는 거의 없을것이다. 반면 엔진은 값어치가 있으므로 자동차와 별개로 단독으로 식별하고 싶을 수 있다.
type Customer struct {
car Car
engine Engine
}
type Car struct {
engine Engine
tires []Tire
wheels []Wheel
}
type Engine struct{}
type Tire struct{}
type Wheel struct{}위의 코드는 참조관계만 간단하게 표현한것이다. Car, Engine은 aggregate root 라고 볼 수 있다. Customer는 aggreage root를 참조할 수 있으나 aggregate내의 Tire는 참조가 불가능하다.
Aggregate를 구성의 장점은 여러 객체간의 참조 관계의 경계선을 정하고 생명주기를 제어하는것에서만 그치지 않는다. 객체간의 관계에서 성립해야 하는 불변식에 대한 일관성도 유지해준다. 만약 타이어의 위치를 변경해주는 rotate 연산이 있다고 가정했을 때 Wheel과 Tire의 ID가 4쌍이 유지되어야 한다는 업무 규칙이 있다면 Car라는 Aggregate 에서 이를 제어해주면 경계가 더 분명해질것이다.
Aggregate를 구현할 때 위와 같은 트랜잭션에도 몇 가지 규칙이 적용된다.
- Root entity는 불변식을 검사해야 한다.
- Root entity는 내부 entity 참조를 다른 객체에 전달할 수 있지만 일시적으로만 사용가능하다. VO를 전달할 때에는 복사본을 전달한다.
- DB 질의를 이용하면 Aggregate Root만 직접적으로 획득하며, 다른 객체 참조는 Aggregate를 탐색해야 한다.
- 삭제 연산은 Aggregate 내의 모든 요소를 한번에 제거해야 한다.
- Aggregate 내의 어떤 객체를 변경해도 전체 Aggregate의 불변식은 지켜져야 한다.
- 예제
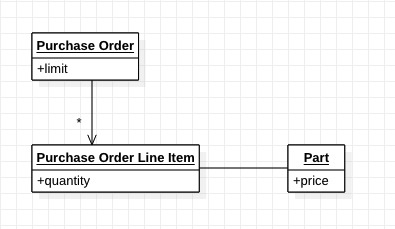
위의 diagram은 단순한 주매 구문 시스템을 나타낸것이다. PO(Purchase Order)에서 "품목 금액의 합 <= 구매 주문 허용한도" 와 같은 불변식이 있다고 가정해보자. 이런 경우 몇 가지 문제점이 있다.
- 불변식 이행: 새로운 Line item이 추가되었을 때 PO의 금액 합이 허용한도를 넘어서면 PO 자체를 무효화로 표시된다.
- 변화 관리: PO의 삭제 저장시 Line item도 삭제 되는데 그에 따른 영향력의 범위를 알 수 없고, Part(품목)의 가격 변동이 발생하면 이 역시 어떤 영향을 줄지 모른다.
- DB 공유: 다수의 사용자가 시스템을 이용하면 경합 문제(race condition)이 발생할 수 있다.
경합 문제를 해결하는 방법에는 여러가지가 있겠지만 특정 객체를 lock을 하는 전략을 구사하기도 한다. 트랜잭션을 commit 하기 전까지 특정 객체(위에서 품목에 해당하는 Part나 주문 PO 자체)를 lock하는 전략을 구사한다고 가정해보자.
- Line item lock: A 사용자가 PO#1의 Item#1을 추가주문하면 해당 Item#1은 lock되기 때문에 B 사용자는 PO#1의 Item#1을 편집할 수 없다. 하지만 Item#2는 편집할 수 있게 되는데 이럴 경우 PO의 허용한도가 초과되는 문제가 발생한다.
- PO lock: 위의 문제를 해결하기 위해 PO 자체를 lock 할 수 있는데, 이럴 경우 문제는 해결되지만 품목(Part)의 가격이 변경되면 역시 불변식이 위반된다.
- Part lock: 문제를 해결할 수 있겠지만 다수의 사용자중 1명이라도 특정 Part를 사용하면 다른 사용자는 해당 Part를 사용할 수 없어서 사용성이 너무 떨어진다.
이 문제를 설계 측면에서 다시 생각해보자. 우선 Part는 여러 PO에서 사용된다. 또한 Part는 PO보다 변경빈도가 낮으며, Part가 변경되었다고 해서 PO에 영향을 주면 안된다. 쇼핑몰에서 10,000원짜리 물건을 주문했는데, 다음날 쇼핑몰에서 해당 물건의 가격을 12,000원으로 올렸다고해서 어제 주문한 Order의 가격이 바뀌는것이 이상적이진 않다.
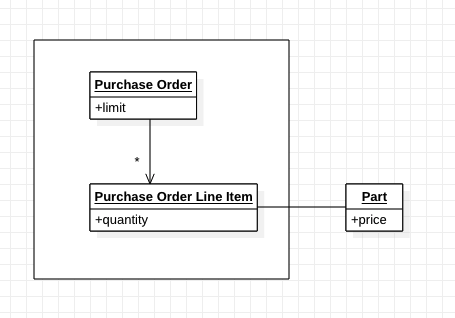
위의 diagram은 PO와 Line item을 하나의 boundary로 묶은것을 표현한것이다. PO에 Line item을 추가할때에는 Part의 price를 복사한다. 이로써 Part의 변동에 따른 불변식의 문제를 해결하였다. 또한 PO 주문을 삭제하는 경우 해당 PO에서 선택한 Line item만 삭제되고, Part는 남게되어 생명주기관리 측면에서도 더 명확해졌다.
'Concepts > SW Design' 카테고리의 다른 글
| DDD - Repository (0) | 2022.09.18 |
|---|---|
| DDD - Factory (0) | 2022.09.12 |
| DDD - Module (package) (0) | 2022.08.07 |
| DDD - Service (0) | 2022.08.07 |
| DDD - Value Object (0) | 2022.07.19 |

댓글