- 출처: 도메인 주도 설계 - 에릭 에반스
- Factory
어떤 객체나 Aggregate를 생성하는 일이 복잡해지거나 혹은 내부 구조가 너무 많이 드러나는 경우 Factory를 통해 캡슐화를 제공할 수 있다.
우리는 자동차를 운전할 때 어떻게 조립 되었느냐는 신경쓰지 않는다. 두 가지 행위는 같은 시간에 일어나지 않으며, 이런 기능이 동일한 매커니즘에 결합되어 있는것은 의미가 없기 때문이다.
이를 객체 생성관점에 빗대어 생각해보면 복잡한 객체를 생성하는 일과 생성된 객체가 하는 일은 관련성이 적다고 생각할 수 있다.
프로그래밍 언어의 기본적인 내용을 학습할 때 main과 같은 함수에서 곧바로 객체를 생성한다. 이런식으로 client가 객체를 생성해서 사용하면 되는데 왜 굳이 Factory를 통해 캡슐화를 하는가? 맨 첫문장을 생각해보면 답을 어느정도 알 수 있다. client가 객체를 직접 생성해서 사용하면 아래와 같은 부작용이 있다.
- client가 도메인 객체의 구조를 알아야하고, 불변식을 수행하려면 동작방식을 알아야 한다.
- client가 도메인 객체와 강하게 결합된다.
복잡한 객체를 생성한다는것은 도메인의 책임이기는 하나 그것이 업무의 모델을 표현하는것은 아니다. 만약 은행 어플리케이션에서 "은행 계좌를 개설한다."와 같은 특수한 경우는 도메인에서 중요한 의미를 갖긴 하지만 일반적으로는 객체의 생성과 조립은 도메인에서 의미가 없다. 하지만 구현 측면에서는 반드시 필요하다.
Factory를 설계하는 방법에는 여러가지가 있지만 어떤 방법을 쓰더라도 기본적으로 아래의 설계 요건은 지켜야 한다.
- 원자성(atomic): 생성된 객체나 aggregate의 불변식을 모두 지켜야 한다. 즉 객체를 생성하는 도중 일관성을 지킬 수 없다고 판단하면 객체 생성을 중지해야 한다.
- 생성된 클래스보다는 생성하고자 하는 타입으로 추상화되어야 한다.
- Factory와 위치 선정
Factory를 만들기로 했다면 제어할 수 있는 어딘가에 위치시켜야 한다. 위치를 결정할때는 보통 aggregate를 중심으로 판단한다.
이미 존재하는 aggregate에 특정 요소를 추가하는 경우를 생각해보자.
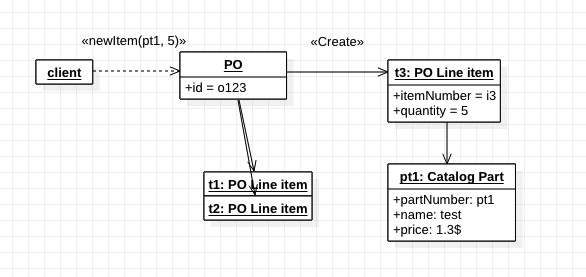
위의 다이어그램은 기존에 존재하는 aggregate PO에 Line item 요소를 추가하는 과정을 나타낸것이다. client는 새로운 item에 대한 Part ID와 수량만 넘겨주면 PO aggregate가 Line item을 추가하고, 무결성을 보장하기 위해 불변식 실행을 담당한다.
Factory method가 반드시 같은 aggregate 내의 객체 생성만 담당하는것은 아니다. 객체간의 밀접한 관련이 있는 경우 다른 aggregate의 객채 생성을 담당하기도 한다.
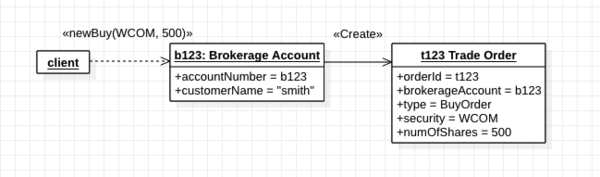
Brokerage Account 정보가 Trade Order에 들어가고(식별성 부여) 어떤 거래를 허용할지에 대한 규칙도 담고 있기 때문에 객체를 생성하는것은 자연스럽다.
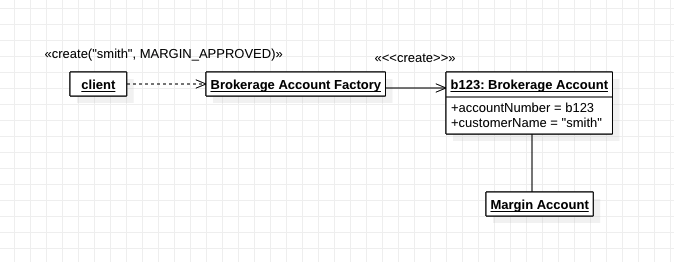
만약 생성과정의 복잡성을 감추어야 한다면 자연스럽지는 않더라도 별도 Factory 객체나 Service를 만들 수 있다.
- Factory vs 생성자
객체를 생성할 때 Factory를 사용하면 많은 이점이 있지만 반드시 그래야하는것은 아니다. 때로는 간단한 생성자를 이용하는것이 더 좋을때도 있다. 만약 아래와 같은 상황이라면 공개 생성자를 사용하는 방식을 고려해보자.
- 클래스가 곧 타입인 경우: 어떤 계층구조도 갖지 않으며, 인터페이스를 구현하는 다형성으로 사용되지 않는 경우
- 클라이언트가 전략을 선택하는 방법으로 구현체에 관심 있는 경우
- 생성자가 복잡하지 않은 경우
- 불변식 로직의 위치
Factory는 자신의 생성물과 특별한 관계를 갖는다. 해당 생성물에 대해 내부 구현을 알고 있으며 밀접한 관계를 갖기 때문이다. 이런 경우 불변식이 생성자가 아닌 Factory에 위치시키면 생성물의 복잡도를 줄이는데 도움이 된다.
단 주의할점은 위와 같은 경우가 Aggregate 규칙에는 잘 맞지만 다른 도메인 객체에 속한 객체를 생성하는 Factory method 의 경우에는 적용되지 않는다.
- Entity factory vs VO factory
VO는 완전 불변성이라서 생성물이 최종 형태이지만 Entity는 앞으로도 변할 가능성이 있기 때문에 유효한 aggregate를 위한 필수속성만 받아들이는 경향이 있다.
Entity에 식별성 할당할 때 해당 로직을 생성자에 둘것이냐 Factory에 둘것이냐가 쟁점이 될 수 있다. 만약 고객의 전화번호를 식별자로 사용하는 경우라면 전화번호를 Factory에 인자로 전달해야 한다. 하지만 내부적으로 증가되는 sequence 라면 Factory가 식별자를 관리하는데 적절한 위치가 될 수 있다.
- 저장된 객체의 재구성
여태까지 객채 생성만을 다루었지만 Factory는 객체를 재구성하기도 한다. 객체를 DB에 저장하거나 네트워크로 전송하려면 직렬화를 하게 되는데 이를 수신하는쪽에서 다시 사용하려면 재구성을 해야 한다.
생성과 거의 비슷하긴 하지만 재구성을 할때에는 아래에 주의해야 한다.
- 재구성 Entity는 신규 ID를 할당하지 않는다. 따라서 재구성 Factory의 입력 매개변수에는 반드시 식별속성이 포함되어 있어야 한다.
- 불변식 위반을 다른 방식으로 처리한다. 생성의 경우 불변식을 위반할 때 생성을 멈추면 되지만 재구성하는 경우에는 좀 더 탄력적으로 대응해야 한다.
객체를 재구성한다고 하면 익숙한 Spring MVC와 같은 구조에서 Repository가 떠오를것이다. DB에 저장된 데이터를 객체로 재구성하는 일이 많기 때문이다. 그렇다면 Factory와 Repository 에는 어떤 차이가 있는가?
- Factory: 객체의 생성과 재구성에 해당하는 생명주기 전이를 캡슐화한다.
- Repository: 저장소에 저장하거나 조회할 때 기술적 복잡성을 노출하는 생명주기 전이를 캡슐화한다.
'Concepts > SW Design' 카테고리의 다른 글
| DDD - 불명확한 개념 (0) | 2022.09.19 |
|---|---|
| DDD - Repository (0) | 2022.09.18 |
| DDD - 도메인 객체의 lifecycle과 Aggregate (0) | 2022.09.10 |
| DDD - Module (package) (0) | 2022.08.07 |
| DDD - Service (0) | 2022.08.07 |

댓글